Last Update: April 24, 2022
Exponential Smoothing: Brown Simple Method in Python can be done using statsmodels package ExponentialSmoothing function found within statsmodels.tsa.holtwinters module for forecasting by flattening time series data with no trend or seasonal patterns. Main parameters within ExponentialSmoothing function are endog with time series data, trend with trend component type, damped_trend with logical value on whether damped trend should be used, seasonal with seasonal component type and initialization_method with initial state values estimation method.
As example, we can do model fitting and forecasting using Brown simple exponential smoothing method for airline passengers with training range as first ten years and testing range as last two years using data included within datasets R package AirPassengers object [1].
First, we import packages pandas for data frames, statsmodels for data downloading and Brown simple exponential smoothing method and matplotlib for its chart [2].
In [1]:
import pandas as pd
import statsmodels.api as sm
import statsmodels.tsa.holtwinters as ets
import matplotlib.pyplot as plt
Second, we create mdata model data object using get_rdataset function, convert mdata object into a data frame using DataFrame function and display first five months of data using print function and head data frame method to view time series structure.
In [2]:
mdata = sm.datasets.get_rdataset(dataname="AirPassengers",
package="datasets",
cache=True).data
mdata = pd.DataFrame(data=mdata["value"]).set_index(
pd.date_range(start="1949", end="1961", freq="M"))
print(mdata.head())
Out [2]:
value
1949-01-31 112
1949-02-28 118
1949-03-31 132
1949-04-30 129
1949-05-31 121Third, we delimit training range for model fitting as first ten years of data and store outcome within tdata object. Then, we delimit testing range for model forecasting as last two years of data and store outcome within fdata object. Notice that training and testing ranges delimiting was only included as an educational example which can be modified according to your needs.
In [3]:
tdata = mdata[:"1958-12-31"]
fdata = mdata["1959-01-01":]
Fourth, we fit Brown simple exponential smoothing method with ExponentialSmoothing function using tdata training range data object and store outcome within tbrown object. Within ExponentialSmoothing function, parameters endog=tdata includes training range data, trend=None includes no trend component type, damped_trend=False includes logical value to not include damped trend, seasonal=None includes no seasonal component and initialization_method="estimated" includes optimized initial state values. Notice that initial state values can also be estimated using heuristic. Also, notice that ExponentialSmoothing function parameters were only included as educational examples which can be modified according to your needs.
In [4]:
tbrown = ets.ExponentialSmoothing(endog=tdata, trend=None,
damped_trend=False,
seasonal=None,
initialization_method=
"estimated").fit()
Fifth, we forecast Brown simple exponential smoothing method with forecast method and store outcome within fbrown object. Within forecast method, parameter steps=len(fdata) includes testing range length as forecasting period. Then, we convert fbrown object into a data frame with DataFrame function. Notice it is important to remember that when doing time series analysis and forecasting, past performance does not guarantee future results.
In [5]:
fbrown = tbrown.forecast(steps=len(fdata))
fbrown = pd.DataFrame(fbrown).set_index(fdata.index)
Sixth, we view Brown simple exponential smoothing method forecast with plot, legend, title, ylabel and xlabel functions. Within plot functions, training range data, testing range forecast and testing range data together with their labels are included and parameter linestyle="--" includes dashed line style. Within legend function, parameter loc="upper left" includes legend location. Within title, ylabel, xlabel functions, chart title, vertical axis label and horizontal axis label strings are included.
In [6]:
plt.plot(tdata, label="tdata")
plt.plot(fbrown, label="fbrown")
plt.plot(fdata, label="fdata", linestyle="--")
plt.legend(loc="upper left")
plt.title("Simple Exponential Smoothing")
plt.ylabel("Air Passengers")
plt.xlabel("Year")
plt.show()
Out [6]: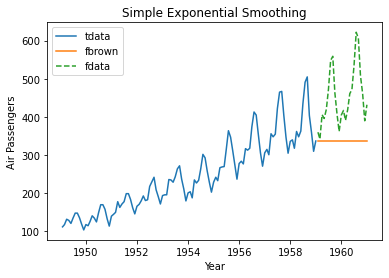
Figure 1. Model fitting and forecasting using Brown simple exponential smoothing method for airline passengers with training range as first ten years and testing range as last two years of data.References
[1] Data Description: Monthly international airline passenger numbers in thousands from 1949 to 1960.
Original Source: Box, G. E. P., Jenkins, G. M. and Reinsel, G. C. (1976). “Time Series Analysis, Forecasting and Control”. Third Edition. Holden-Day. Series G.
Source: datasets R Package AirPassengers Object. R Core Team (2021). “R: A language and environment for statistical computing”. R Foundation for Statistical Computing, Vienna, Austria.
[2] pandas Python package: Wes McKinney. (2010). Data Structures for Statistical Computing in Python, Proceedings of the 9th Python in Science Conference, 51-56.
statsmodels Python package: Seabold, Skipper, and Josef Perktold. (2010). “statsmodels: Econometric and statistical modeling with python”. Proceedings of the 9th Python in Science Conference.
matplotlib Python package: John D. Hunter. (2007). Matplotlib: A 2D Graphics Environment. Computing in Science & Engineering, 9, 90-95.